Convolutional Neural Network
A convolutional neural network (CNN) is a deep learning architecture designed for processing structured grid data such as images, using learnable convolutional filters that detect spatial features like edges, textures, and shapes. The network stacks convolutional layers (feature extraction) with pooling layers (spatial downsampling) and fully connected layers (classification). CNNs revolutionised computer vision after AlexNet won the ImageNet competition in 2012 with significantly lower error rates than prior methods.
Key Formula
Discrete 2D convolution: (f * g)[i,j] = sum over m,n of f[m,n] × g[i-m, j-n]
LaTeX: (f * g)[i,j] = \sum_m \sum_n f[m,n] \cdot g[i-m, j-n]
| Symbol | Meaning | Unit |
|---|---|---|
| f | Input feature map (or image) | pixel intensity |
| g | Convolutional filter (kernel) | learnable weights |
| (f * g)[i,j] | Output activation at position (i, j) | activation units |
| m, n | Kernel spatial indices | pixels |
CNN Layer Types and Their Roles
| Layer Type | Operation | Output Size Effect | Parameters | Role |
|---|---|---|---|---|
| Convolutional | Dot product with filter | Reduces by (k-1) | k×k×C_in×C_out + bias | Feature extraction |
| ReLU Activation | max(0, x) | Unchanged | 0 | Non-linearity |
| Max Pooling | Max within window | Halved (typical) | 0 | Spatial downsampling |
| Batch Norm | Normalise per batch | Unchanged | 2×channels | Training stability |
| Fully Connected | Matrix multiplication | Flattened vector | n_in × n_out + bias | Classification |
| Softmax | Probability distribution | n_classes | 0 | Output probabilities |
Interactive Tools
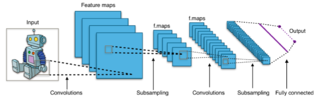
Wikimedia Commons, CC BY-SA
Related Terms
Transformer (AI)
The Transformer is a deep learning architecture introduced by Vaswani et al. in 2017 that relies entirely on self-attention mechanisms rather than recurrence or convolutions to model relationships between all positions in a sequence in parallel. It consists of an encoder–decoder structure with multi-head attention, positional encodings, and feed-forward layers. Transformers are the foundation of modern large language models including BERT, GPT, T5, and PaLM, and have also been applied to vision, audio, and multimodal tasks.
Natural Language Processing
Natural language processing (NLP) is a field of artificial intelligence focused on enabling computers to understand, interpret, and generate human language in a useful way. It combines computational linguistics with machine learning and deep learning to process text and speech data. Core tasks include tokenisation, named entity recognition, sentiment analysis, machine translation, and question answering.
Transfer Learning
Transfer learning is a machine learning technique where a model trained on one large task is adapted (fine-tuned) for a different but related task, leveraging previously learned representations instead of training from scratch. It dramatically reduces the data and computation required for new tasks by reusing features such as edges in vision models or syntactic patterns in language models. Transfer learning is foundational to modern AI, enabling pre-trained models like ResNet, BERT, and GPT to be fine-tuned for specialised applications with small datasets.
The term "convolutional" refers to the mathematical convolution operation. The architecture was first described by Yann LeCun et al. in 1989 (LeNet), building on work by Fukushima's neocognitron (1980). "Neural network" traces to Warren McCulloch and Walter Pitts (1943).