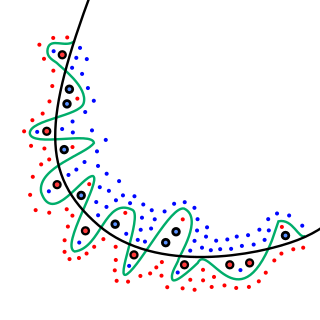
Overfitting
Overfitting occurs when a machine learning model learns the training data too well — including its noise and random fluctuations — to the point where it performs poorly on new, unseen data. An overfitted model has high training accuracy but low validation/test accuracy, indicating it has memorized patterns specific to the training set rather than generalizing. Overfitting is more likely with complex models, small datasets, or insufficient regularization.
Overfitting vs Underfitting vs Good Fit
| Scenario | Training Error | Validation Error | Symptom | Fix |
|---|---|---|---|---|
| Underfitting | High | High | Model too simple | Increase model complexity |
| Good Fit | Low | Low (similar) | Balanced generalization | None needed |
| Overfitting | Very low | High | Model memorized data | Regularization, more data |
| Severe Overfitting | Near zero | Very high | Noise memorized | Simpler model, dropout |
Interactive Tools
Wikimedia Commons, CC BY-SA
Related Terms
Cross-Validation
Cross-validation is a statistical technique for evaluating a machine learning model's ability to generalize to an independent dataset. The most common form, k-fold cross-validation, partitions the training data into k equally sized subsets; the model is trained on k−1 folds and evaluated on the remaining fold, repeating this process k times and averaging the results. Cross-validation provides a more reliable performance estimate than a single train-test split and helps in selecting hyperparameters and comparing models.
Supervised Learning
Supervised learning is a machine learning approach where a model is trained on a labeled dataset, meaning each training example is paired with the correct output (label). The model learns a mapping from inputs to outputs by minimizing the difference between its predictions and the true labels. It is the most widely used ML paradigm and underpins applications such as image recognition, speech transcription, and credit scoring.
Machine Learning
Machine learning is a branch of artificial intelligence in which systems learn from data to improve their performance on tasks without being explicitly programmed for each task. It works by identifying statistical patterns in training data and using those patterns to make predictions or decisions on new, unseen data. Machine learning powers applications ranging from spam filters and recommendation engines to medical diagnosis and autonomous vehicles.
"Overfitting" is a compound formed from "over" (Old English "ofer," meaning excessively) and "fit" (to conform closely to). The concept was recognized in statistical modeling in the mid-20th century and became central to machine learning theory in the 1990s.